
858
0
详细信息
AI 药物研发情报系统项目方案,很详细!
目录
一、项目背景
1.1 新药研发的时代命题
1.2 行业痛点与情报需求
1.3 技术驱动的范式变革
1.4 项目定位与战略目标
二、业务痛点
2.1 情报分散与获取效率低下
2.2 知识碎片化与洞察缺失
2.3 情报时效性与前瞻性不足
2.4 报告生成与知识复用困难
三、解决方案与技术实现
3.1 总体技术架构
3.2 模块一:多源数据整合与标准化
3.2.1 化学药数据整合
3.2.2 生物药数据整合
3.2.3 中药数据整合
3.2.4 细胞与基因治疗数据整合
3.2.5 寡核苷酸药物数据整合
3.3 模块二:多维异质知识图谱构建
3.3.1 化学药知识图谱
3.3.2 生物药知识图谱
3.3.3 中药知识图谱
3.3.4 细胞与基因治疗知识图谱
3.3.5 寡核苷酸知识图谱
3.4 模块三:智能检索与问答引擎
3.4.1 RAG架构设计
3.4.2 核心问答场景
3.5 模块四:情报报告自动生成
3.5.1 靶点调研报告模板
3.6 模块五:竞争监测与预警
3.6.1 监测维度
3.6.2 预警机制
四、价值成果
4.1 效率提升
4.2 决策质量提升
4.3 知识资产沉淀
五、项目风险与应对策略
5.1 数据质量风险
5.2 大模型幻觉风险
5.3 数据合规风险
六、项目建设周期
七、算力需求推荐方案
一、项目背景
1.1 新药研发的时代命题
当前,全球新药研发正处于深刻变革期。据德勤报告,2023年一款新药的平均研发成本已攀升至约23亿美元,而研发周期通常需要10-15年。在这一背景下,药物研发情报作为连接基础研究与商业决策的核心枢纽,其价值日益凸显。
从药物类型维度来看,当前制药企业的研发管线呈现出多元化格局:
化学药:仍是主流,1类新药聚焦全新靶点或作用机制,改良型新药追求me-better/me-too差异化
生物药:单克隆抗体、重组蛋白快速增长,1类新药强调靶点创新,改良型新药聚焦给药便利性
中药:经典名方二次开发、组分创新成为热点,强调中西医双循证
细胞与基因治疗:以1类新药为主,聚焦基因编辑、CAR-T等前沿领域
寡核苷酸/小核酸药物:新兴赛道,1类新药侧重序列设计与递送系统创新
面对如此多元的研发管线,传统的药物研发情报体系已难以支撑决策需求。构建智能化的药物研发情报系统,是制药企业提升研发效率、降低决策风险的核心基础设施。
1.2 行业痛点与情报需求
靶点选择困境: 靶点是药物研发的起点,也是决定研发成败的关键。据Nature Reviews Drug Discovery统计,约50%的药物研发失败源于靶点选择错误。面对海量靶点信息,研发团队需要系统性评估靶点的成药性、竞争格局、专利风险,但传统情报获取效率低下。
化学药情报需求:需要整合靶点验证文献、化合物活性数据、合成路线专利、晶型专利等信息,为1类新药靶点发现与改良型新药结构优化提供支撑。
生物药情报需求:需要追踪靶点表达分布、功能验证数据、抗体序列专利、表达系统专利等,支持1类新药靶点创新与改良型新药人源化/亲和力优化。
中药情报需求:需要关联方剂组方规律、成分药理作用、疾病证候网络,为组分创新与经典名方二次开发提供循证依据。
细胞与基因治疗情报需求:需要追踪CRISPR/Cas9、CAR-T、TCR-T等前沿技术的专利布局、临床进展、脱靶效应数据等。
寡核苷酸药物情报需求:需要关注序列设计专利、递送系统(GalNAc、LNP)专利、修饰专利等前沿情报。
1.3 技术驱动的范式变革
人工智能技术的突破为药物研发情报带来了根本性变革:
知识图谱技术:能够将分散的靶点、疾病、药物、专利等实体构建为关联网络,支持多跳推理与路径发现
大语言模型(LLM):能够理解专业文献语义,实现智能问答与报告自动生成
自然语言处理(NLP):能够从海量文献中自动抽取实体、关系与事件,大幅提升情报采集效率
图神经网络(GNN):能够挖掘靶点-疾病网络的深层拓扑特征,辅助靶点优先级排序
1.4 项目定位与战略目标
本项目旨在为制药企业构建一套基于知识图谱与大模型的智能药物研发情报系统,实现:
近期目标(6个月):
完成化学药、生物药、中药、细胞与基因治疗、寡核苷酸药物五大类药物的情报数据整合
构建覆盖"基因-靶点-蛋白-通路-疾病-药物"的核心知识图谱
上线基于检索增强生成(RAG)的智能问答与报告生成功能
中期目标(12个月):
实现情报自动采集、实时更新、智能推送
构建靶点优先级评估与竞争格局分析模型
接入企业内部实验数据,形成私域知识网络
战略目标:
将情报系统打造为研发决策的核心支撑平台
实现从"信息检索"到"情报洞察"的根本升级
沉淀企业级药物研发知识资产
二、业务痛点
2.1 情报分散与获取效率低下
跨库检索困境: 药物研发情报分散于数十个专业数据库:PubChem、ChEMBL、UniProt、PDB、ClinicalTrials、TCMSP、TCMID等。不同数据库的检索接口、数据格式、更新频率各异,研发人员需要在多个系统间频繁切换。
具体表现:
化学药研发团队需要同时检索SciFinder、Reaxy获取化合物活性数据
生物药研发团队需要查阅Abcam、BioLegend获取抗体序列与验证数据
中药研发团队需要整合TCMSP、TCMID、ETCM等多个中药数据库
细胞与基因治疗团队需要追踪CRISPR、Addgene等特定领域数据库
效率损耗:据统计,研发人员平均花费30%以上的工作时间用于文献检索与信息收集,其中大量时间为重复性、机械性的跨库检索工作。
2.2 知识碎片化与洞察缺失
关联断裂问题: 传统数据库以"表"为基本组织单元,实体间的关系需要人工串联。以靶点调研为例,研发人员需要手动关联:靶点基因功能→相关疾病→已有药物→竞争格局→专利风险→文献证据,这条完整的情报链路往往需要跨5-10个数据库、阅读数十篇文献才能建立。
化学药洞察缺失:难以系统性了解靶点的结构-活性关系(SAR)、代谢稳定性数据、成药性参数,缺乏对化合物优化方向的系统洞察。
生物药洞察缺失:难以全面评估靶点的种属差异、免疫原性风险、规模化生产工艺挑战,缺乏对生物药开发难点的预判。
中药洞察缺失:难以建立"成分-靶点-通路-证候"的多维关联,难以形成中西医双循证的证据链。
细胞与基因治疗洞察缺失:难以追踪脱靶效应、安全性数据 CMC挑战的最新进展,缺乏对商业化可行性的全面评估。
寡核苷酸药物洞察缺失:难以全面了解递送系统的专利壁垒、序列同源性分析、脱靶预测结果。
2.3 情报时效性与前瞻性不足
信息滞后问题: 从文献发表到进入企业内部知识库,通常存在数周至数月的时滞。对于竞争激烈的热门靶点,这种时滞可能意味着错失最佳决策窗口。
竞争监测不足: 难以实时追踪竞品的研发进展、临床数据、专利动态。当竞品发布重磅数据时,企业往往反应滞后。
趋势研判缺失: 缺乏对药物研发管线、治疗范式变迁、新兴技术突破的系统性追踪与预判能力。
2.4 报告生成与知识复用困难
人力瓶颈: 靶点调研报告、行业分析报告需要耗费大量人力进行数据提取、图表制作、文字撰写。据调研,一份完整的靶点调研报告平均需要3-5个工作日。
质量参差: 不同人员撰写的报告在格式、内容深度、分析框架上差异较大,难以形成统一的知识沉淀标准。
知识流失: 项目结题后,相关情报与洞察难以系统化沉淀。当新项目启动时,往往需要从零开始,历史积累的情报价值无法最大化。
三、解决方案与技术实现
3.1 总体技术架构
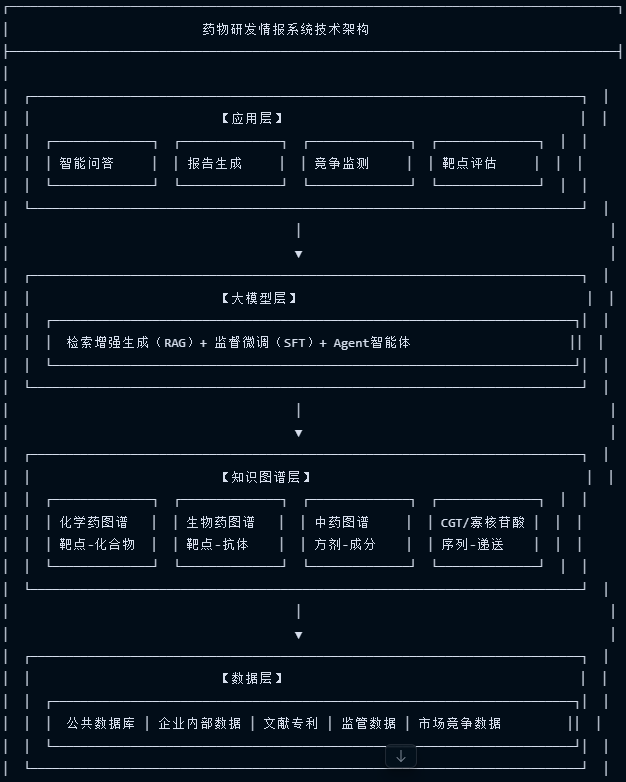
图源:摩熵医药案例报告-药物研发情报系统项目方案
3.2 模块一:多源数据整合与标准化
3.2.1 化学药数据整合
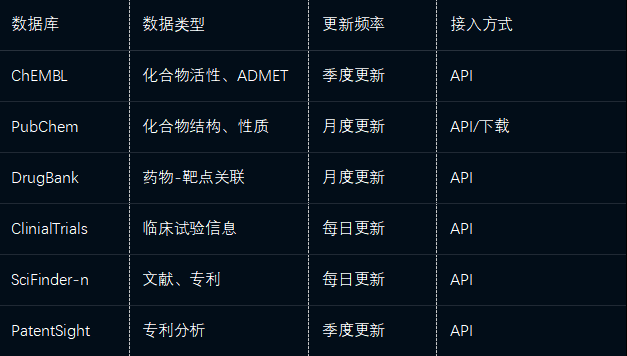
关键处理:
化合物标准化:采用InChI Key作为唯一标识,SMILES用于结构检索
靶点标准化:统一映射至UniProtKB Accession ID
活性数据标准化:统一Ki/Kd/IC50/EC50等活性指标表述
3.2.2 生物药数据整合
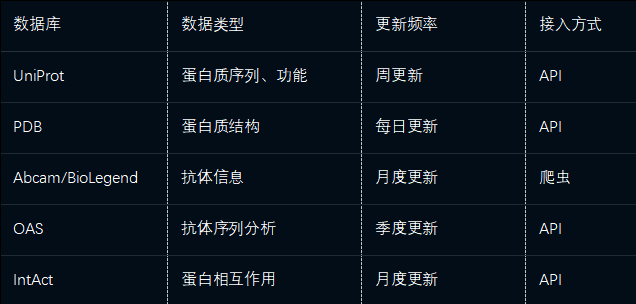
关键处理:
抗体序列标准化:采用Kabat/IMGT编号体系
靶点-抗体关联:整合实验验证与计算预测数据
免疫原性评估:整合T细胞表位、B细胞表位预测数据
3.2.3 中药数据整合
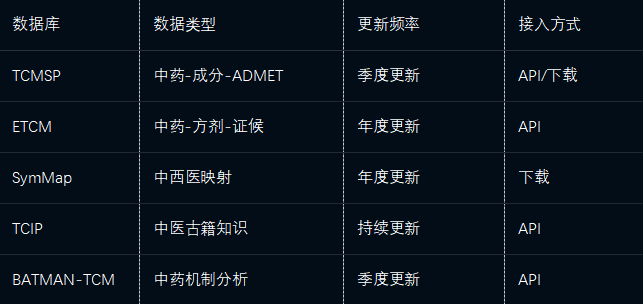
关键处理:
中药标准化:基于《中国药典》统一基原名称,建立别名映射
成分标准化:以CAS号为唯一标识,整合多库数据
证候标准化:建立中医证候-西医症状-疾病映射关系
3.2.4 细胞与基因治疗数据整合
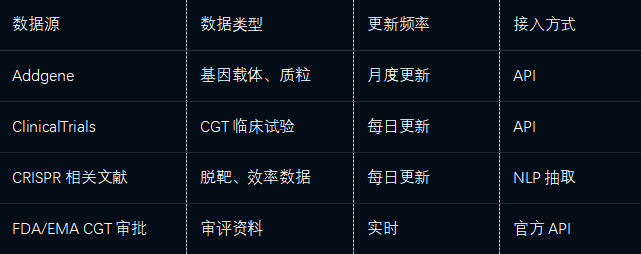
关键处理:
基因序列标准化:采用基因组坐标体系(GRCh38)
载体类型区分:病毒载体(AAV、LV)、非病毒载体(LNP、质粒)
适应症映射:罕见病/肿瘤等多维度分类
3.2.5 寡核苷酸药物数据整合
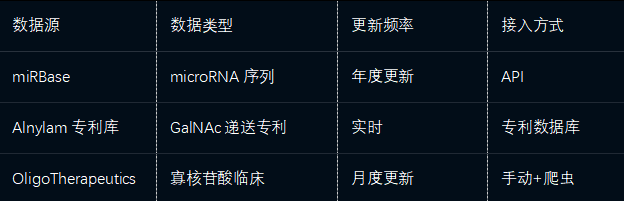
关键处理:
序列标准化:统一5'-3'方向表述
修饰标注:PS、MOE、2'-F/2'-O-Me等修饰类型标注
递送系统分类:GalNAc、LNP、脂质体等分类
3.3 模块二:多维异质知识图谱构建
3.3.1 化学药知识图谱
核心实体:
化合物(Compound):分子式、SMILES、分子量、CAS号
靶点(Target):基因名、UniProt ID、蛋白家族、功能描述
疾病(Disease):ICD-10编码、DOID、疾病描述
通路(Pathway):KEGG ID、通路描述、上下游分子
专利(Patent):专利号、权利要求、有效期
核心关系:
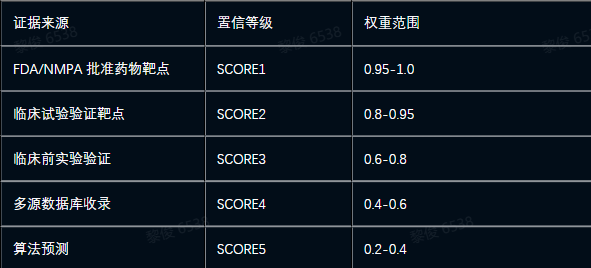
化合物—[作用于]→靶点(亲和力数据:Ki/Kd/IC50)
化合物—[用于治疗]→疾病(适应症)
靶点—[参与]→通路
靶点—[关联]→疾病(遗传证据等级)
化合物—[受专利保护]→专利
置信权重体系:
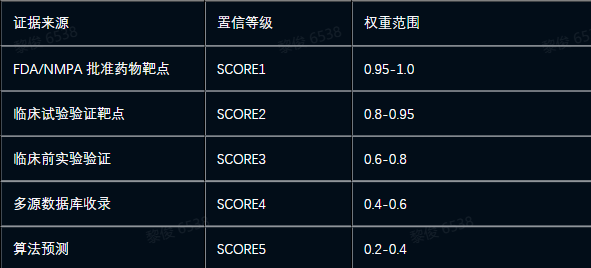
3.3.2 生物药知识图谱
核心实体:
抗体(Antibody):轻重链序列、CDR区、亲和力
靶点(Target):胞外域、结构类型(单次跨膜/多次跨膜/可溶性)
给药系统(Delivery):注射/皮下/口服、制剂配方
免疫原性(Immunogenicity):ADA发生率、风险等级
核心关系:
抗体—[特异性结合]→靶点(KD值)
抗体—[属于]→抗体类型(单抗/双抗/ADC)
靶点—[表达于]→组织/细胞类型
抗体—[具有]→免疫原性风险
3.3.3 中药知识图谱
核心实体:
方剂(Formula):组成、剂量、制法、功效
中药(Herb):基原、性味归经、功效
成分(Ingredient):化学成分、含量、提取来源
证候(Syndrome):中医证候、症状组合
靶点(Target):成分作用靶点
核心关系:
方剂—[组成]→中药
中药—[含有]→成分
成分—[作用于]→靶点
靶点—[干预]→疾病
疾病—[对应]→证候
3.3.4 细胞与基因治疗知识图谱
核心实体:
基因(Gene):基因名、基因组位置、基因功能
载体(Vector):载体类型、容量、安全性特征
细胞产品(Cell Product):CAR结构、转染方式
适应症(Indication):疾病、治疗线、患者人群
核心关系:
基因—[编辑]→靶基因(敲除/敲入/点突变)
载体—[递送]→基因
细胞产品—[靶向]→靶点
靶点—[高表达于]→肿瘤/组织
3.3.5 寡核苷酸知识图谱
核心实体:
序列(Sequence):核苷酸序列、修饰类型、长度
靶标(Target):RNA序列、基因组位置
递送系统(Delivery):GalNAc/LNP/裸寡核苷酸
脱靶位点(Off-target):预测脱靶序列、脱靶分数
核心关系:
寡核苷酸—[靶向]→RNA靶标
寡核苷酸—[使用]→递送系统
递送系统—[具有]→肝/组织特异性
寡核苷酸—[可能脱靶]→脱靶位点
3.4 模块三:智能检索与问答引擎
3.4.1 RAG架构设计
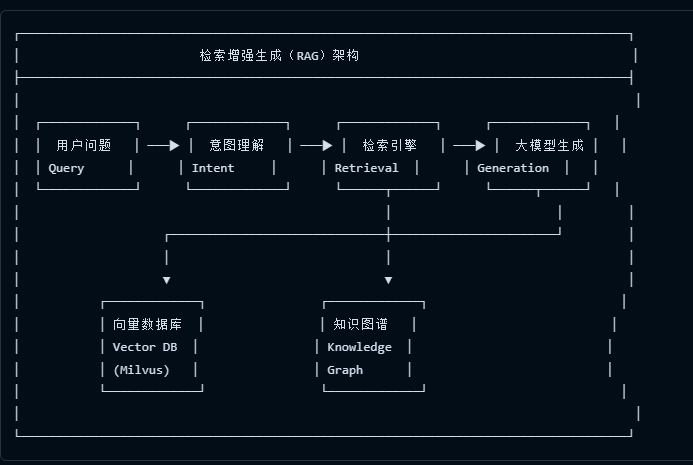
图源:摩熵医药案例报告-药物研发情报系统项目方案
3.4.2 核心问答场景
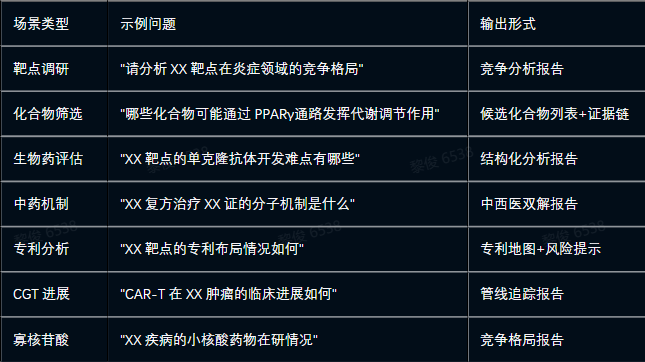
3.5 模块四:情报报告自动生成
3.5.1 靶点调研报告模板

图源:摩熵医药案例报告-药物研发情报系统项目方案
3.6 模块五:竞争监测与预警
3.6.1 监测维度
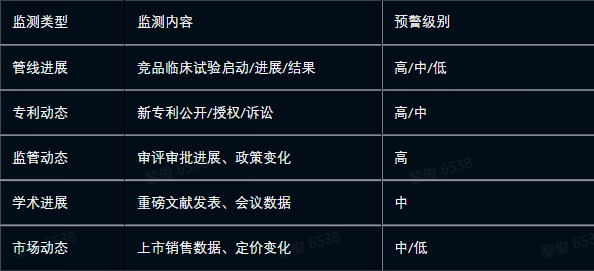
3.6.2 预警机制
即时推送:竞品重要进展实时推送至相关研发团队
周报汇总:每周汇总竞争情报,发送至管理层
月度分析:深度分析竞争格局变化,输出策略建议
四、价值成果
4.1 效率提升
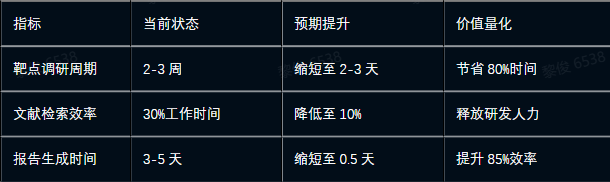
4.2 决策质量提升
靶点选择更科学:基于多维数据综合评估,降低靶点失败风险约30%
竞争情报更全面:实时追踪竞品动态,避免信息不对称导致的决策失误
专利布局更精准:专利风险前置识别,降低侵权风险
4.3 知识资产沉淀
企业知识库:形成覆盖五大药物类型的结构化情报知识库
历史积累复用:历史项目情报可检索、可复用
能力持续提升:AI模型持续学习,情报能力随时间迭代增强
五、项目风险与应对策略
5.1 数据质量风险
风险描述:多源数据存在重复、冲突、缺失等问题,影响情报准确性。
应对策略:
建立数据质量评分体系,对数据源进行A/B/C分级
实施数据清洗标准化流程,去重、消歧、补全
设置置信度标签,低置信度数据明确提示
5.2 大模型幻觉风险
风险描述:大模型可能生成看似合理但实际错误的情报。
应对策略:
强制RAG架构,生成内容必须基于检索证据
设置"无证据不生成"机制,避免虚构
关键情报设置人工复核机制
5.3 数据合规风险
风险描述:整合外部数据可能涉及知识产权或使用授权问题。
应对策略:
仅接入具有合法使用权的数据库
企业内部数据严格隔离,不对外输出
定期进行数据合规审计
六、项目建设周期
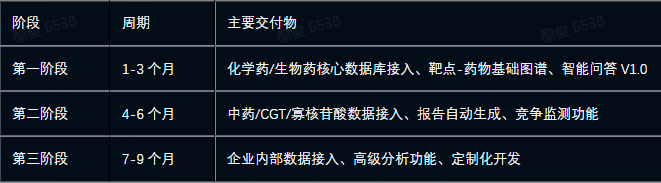
七、算力需求推荐方案

(参考资料:摩熵医药案例报告-药物研发情报系统项目方案)
随机推荐