
623
0
国内外主流应用的核酸数据集及API接口的应用
介绍国内外主流应用的核酸序列数据库及核酸数据接口API的应用,展示核酸序列本身、序列描述、序列长度以及分子类型等核心元数据字段,帮助大家构建完整的核酸数据获取工作流。
推荐指数:
详细信息
国内外主流应用的核酸数据集及API接口的应用
在生物信息学研究中,核酸序列数据是最基础也是最重要的数据类型之一。无论是进行基因组学分析、进化生物学研究,还是分子生物学实验设计,获取准确、完整的核酸序列信息都是必修课。随着高通量测序技术的飞速发展,全球核酸序列数据呈爆炸式增长,如何高效、精准地通过API接口获取这些序列数据,是每一位生物信息学从业者值得思考的问题。
笔者将系统介绍国内外主流应用的核酸序列数据库及核酸数据接口API的应用,展示核酸序列本身、序列描述、序列长度以及分子类型等核心元数据字段,帮助大家构建完整的核酸数据获取工作流。
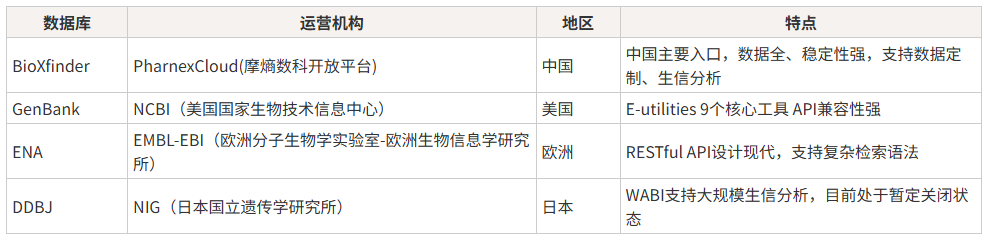
一、主流核酸数据及来源介绍
美、欧、日3个国际核酸序列数据库协作联盟就不做详细介绍,3家数据库每日交换数据,确保内容同步。因此,同一序列在三家数据库中的核心信息(序列、描述、长度、分子类型)完全一致,仅格式和访问方式有所差异。
而中国的摩熵数科开放平台,则是同步收载其国际核酸序列数据。在其生化分子API接口栏目下公开展示了摩熵生物数据库中的4000万+条核酸数据,覆盖人、大鼠、小鼠三个物种,记录包含核酸序列、序列描述、序列长度、分子类型等信息,并提供生物数据库定制化服务。
二、核酸API接口数据字段一览
以摩熵数科平台的核酸数据API为例,下面是其数据结构及样例展示。
{
"数据ID":"2",
"核酸检索号": [
"CM001971",
"AMYH02000000"
],
"序列描述": "Homo sapiens mitochondrion, complete sequence, whole genome shotgun sequence.",
"locus": {
"序列长度": "16562",
"分子类型": "DNA",
"分子拓扑": "circular",
"分区编号": "CON",
"更新时间": "2016-10-25"
},
"版本号": "CM001971.1",
"来源": {
"物种来源": "mitochondrion Homo sapiens (human)",
"物种名称": "Homo sapiens",
"谱系": [
"Eukaryota",
"Metazoa",
"Chordata",
"Craniata",
"Vertebrata",
"Euteleostomi",
"Mammalia",
"Eutheria",
"Euarchontoglires",
"Primates",
"Haplorrhini",
"Catarrhini",
"Hominidae",
"Homo"
]
},
"参考文献": [
{
"作者": [
"Steinberg,K.M.",
"Schneider,V.A.",
"Graves-Lindsay,T.A.",
"Fulton,R.S.",
"Agarwala,R.",
"Huddleston,J.",
"Shiryev,S.A.",
"Morgulis,A.",
"Surti,U.",
"Warren,W.C.",
"Church,D.M.",
"Eichler,E.E.",
"Wilson,R.K."
],
"标题": "Single haplotype assembly of the human genome from a hydatidiform mole",
"文献": "Genome Res. 24 (12), 2066-2076 (2014)",
"pubmed号": "25373144"
}
],
"原始序列": "xxx"
}
三、核酸序列数据的进化
随着生物数据量的持续增长,API接口的稳定性和性能也在不断优化。2026年初,摩熵生物已完成多个渠道生信数据AI agent,NCBI对PMC E-utilities的升级,ENA也持续扩展其REST API的功能覆盖。建议研究者持续关注各平台的官方文档更新,及时调整数据获取策略。
以上就是笔者关于常用核酸数据接口的简单介绍,可以从这些平台系统、高效地获取所需的序列数据及其核心元数据——序列描述、长度和分子类型。最后强盗一下,大家务必遵守各平台的速率限制,避免被封禁的可能。
随机推荐