

825
0
医疗数据现状与大数据的应用【科研数据集分享】
通常情况下,被动收集的数据质量往往不如主动收集的数据。原因在于,在收集数据时缺乏明确的目标,就无法构建起一套完整的数据记录体系,从而导致数据的完整性、准确性和颗粒度都难以保证,进而出现数据缺失、不规范和非结构化等问题。而大多数医院信息系统主要是服务于医院的诊疗流程,其数据收集方式是尽可能多地存储数据,却缺乏精细的质量控制和标准规范。
推荐指数:
详细信息
医疗数据现状与大数据的应用【科研数据集分享】
美国阿肯萨斯州有块地,早年是钻石矿,因矿脉太稀被弃;现在改成钻石公园,谁都能进去翻土,翻到了钻石可直接揣走。新闻里常有人“随手一捡就是十几克拉”的传奇。我开了几千公里,晒了两天大太阳,淘了几十公斤泥,颗粒无收,蹲在那被翻了几遍的土丘上顿悟:医疗大数据就像这片地——理论上遍地宝藏,实际上大多数人只晒脱一层皮,手里剩一把土。
而如今,在医疗大数据里淘金的人,其实都在吃土。
于是,国内便冒出这么一副尴尬景象:多年前,不知谁在村头吼了一嗓子“后山泥地有钻石!”——声音一落,凡是有把子力气的后生全扛起铁锹、推着小车涌向后山。几年一晃,家家院里黄土成山,猪圈被占、鸡窝被压,却从不见有人来高价收购。自己天蒙蒙亮就下地,傍晚收工仍蹲院里筛土,一箩接一箩,连星点宝光都没见。可没人甘心,仍日日守着那堆土,逢邻居便拍胸脯夸自家土“又多又纯”,说完背手晃悠,只剩心底一阵惘然。
先说一说医疗数据这些土
声明一下,鉴于个人经历所限,我接触的医疗数据主要是医院的临床数据,所以本文讨论的医疗数据也仅限于此。对于基因组数据、移动医疗中的健康监测数据,我暂且不敢多言。
接触了不少医疗行业的“大数据”数据集,其中一些甚至是整合了多个地市甚至省份的医院HIS全数据,感触颇深。如果要用一个词来形容我对医疗大数据的感受,那就是“鸡肋”。面对海量的医疗数据,不储存起来觉得可能会错过巨大的价值,存下来又不知道该如何有效挖掘。看着服务器负荷越来越重,只能徒增烦恼。
数据本身种类繁多,有些是无心或有意随手记录的,比如各种日志、浏览记录等;还有一些是刻意收集的,比如问卷等。目前的临床数据集,除了少数特定研究目的的前瞻性数据集外,大多还是日常记录的流程数据,像医院信息系统(HIS、LIS、PACS等)产生的数据。
通常情况下,被动收集的数据质量往往不如主动收集的数据。原因在于,在收集数据时缺乏明确的目标,就无法构建起一套完整的数据记录体系,从而导致数据的完整性、准确性和颗粒度都难以保证,进而出现数据缺失、不规范和非结构化等问题。而大多数医院信息系统主要是服务于医院的诊疗流程,其数据收集方式是尽可能多地存储数据,却缺乏精细的质量控制和标准规范。因此,大量的真实世界数据往往是质量低下的“垃圾”数据,而将这些“垃圾”数据简单地堆砌在一起,就形成了所谓的大数据。
另一方面,有目的性地收集的数据也并非完美无缺。首先,收集这类数据往往需要投入大量的时间和精力,这也使得很少有高质量数据能够达到“大数据”的规模。其次,一旦明确了特定的收集目的,数据的适用范围就会受到限制。在许多情况下,当这些数据被用于其他场景时,常常会出现不适用、缺失关键信息等问题。
说绝一点,不是小而美,就是大而丑。
当数据集又大又差时,哪怕里面有钻石,也会给挖掘带来极大困难。在极端情况下,一些人就像开头那个故事里的人一样,会放弃这个不值钱的矿山(土丘),转而去研究那些医疗领域的小数据。
由于这里讨论的是大数据,那么接下来主要聚焦于大而丑的这坨土
这里插一段,因为最近一直在做国家统一收集的医疗大数据集的数据治理(这个整合、质控、标准化的过程极其考验水平),就我们来看,医疗大数据没有产出的一个很大前置原因是根本没有进行数据治理,整合的大数据根本不能用!
这里总结几条收集数据时的想法,希望能为今后的数据采集方提供新的视角(仅供参考,个人之言)。
① 尽量保存完整信息。
医学的每一个领域都非常复杂,在诊疗流程中,有大量的信息点可以用于后续的临床质量提升或新治疗方案的开发。这也是为什么制药公司会花费高昂成本在临床试验中采集变量,形成病例报告表(CRF)。尽管在日常工作中无法像临床试验那样严谨对待数据,但至少要保存本病种或专科领域患者所需的所有信息。要知道,后续有许多技术(比如我们正在做的病历自然语言信息抽取)可以从这些信息中提取并结构化数据。但如果原始信息本身就缺失,那么再强大的巧妇也难为无米之炊。
②尽可能带着明确的目的存储数据(这个目的最好具有普适性)。
严格来讲,目前医院中的数据集几乎没有达到“科研数据集”或“临床试验数据集”的标准。一个重要原因在于收集数据时的盲目性。如果对某个特定病种或某一类人群没有进行相对明确的医学体系梳理,那么无论花多少时间把患者信息抄到 Excel 里,这些数据都是片面的。等到真正要做统计分析时,才发现各种数据缺失,甚至在开展多中心研究时才发现不同医院“精心”收集的患者信息根本无法匹配。在这方面,可以参考一些优秀的临床数据模型,以确保变量的有序组织。关于这一点,如果深入展开又是一篇大作,这里暂不详细讨论。
③建立数据语义级标准和良好的收集习惯。
简单来说,如果研究者已经保存了完整的信息,并且有机制保证这些信息点可以共享和复用,那么接下来就是通过一些细节来进一步提升数据质量。这里强调的语义级标准是指在信息点有多种表述方式时,如何实现相互统一。例如,最经典的例子是二型糖尿病的表述可能有数十种(医生应该深有体会),但要让计算机明白这些表述说的是同一件事。在这方面,虽然很多人提出用知识库来规范医生的思维和书写方式,但我们更倾向于训练我们的人工智能模型,使其学会“理解”(注意不是简单的关键词匹配)语言信息。这样一来,当我们的 AI 面对几乎无限种描述方式时,就不会像其他方案那样因知识库词汇的局限性而受限。至少从目前来看,二型糖尿病这类任务对我们已经不再是问题。
刚才讲了医学数据的本质,接下来再聊聊这坨土里能挖出什么(医疗数据的应用)。
正是因为前几年其他一些领域的人创造性地从“垃圾”大数据中挖出了商业应用(比如从历史浏览或购买记录中做精准广告推荐,从社交网络中挖掘时事热点等),大众才对“大数据”产生了莫名的期待。所以,其他领域的大数据应用就是那个在村口喊地里有钻石的人。
因此,一直以来,医疗行业的大数据都被大家视为珍宝,人们坚信这些数据中蕴含着极高价值。然而,事实上,除了临床回顾性分析和各种炫酷的BI可视化界面外,我们鲜少看到真正令人眼前一亮的大数据应用。前几年,还能通过数据画出一些好看的图表(好在大数据行业的图表确实美观),做一些统计给领导看。但如今,领导们对这些图表也逐渐审美疲劳,于是,那些拥有大数据的机构纷纷感到前路茫茫,有心无力。
那到底是什么原因导致了这种困境呢?
其实很简单,就两个字:隐私。
试想一下,其他领域大数据最赚钱的应用是精准营销,那么在医疗行业真的做不到吗?如果患者的就诊信息能像你的浏览记录那样被人获取,比如你第一天去医院看了男科,第二天所有网页广告栏就都给你推送羞羞的药物和手术方案,那医疗大数据的路早就走通了!
可惜(幸好)这种情况还没发生。病人隐私高于一切!(所以别抱怨医院有多封闭、多麻烦,要是真方便了,说不定你会遇到更大的麻烦)。就这样,医疗大数据变现最光鲜亮丽的一扇大门关上了。
没事,明路不通咱就走暗道!一些聪明人把目光瞄准了另一个方向:医生。药虽然是患者购买,但开药的可是医生啊!要是我能掌握医生开药的信息,再去有针对性地安排我的医药代表,这不也是一种“精准营销”吗!于是,医疗大数据变现的第二条路出现了:找人简单统计一下医生每个月开了多少药,然后根据这些数据精准地给医生一些好处。这样一来,医生既有动力又有压力去开你家的药,这不是皆大欢喜?
那就把父母官想简单了,这些私下里的小把戏,不是在助长医疗行业的不正之风吗?而且,一些本不想让外界知道的信息反而被你们泄露出去,这还了得?!于是,这种商业路径有了个新名字:“统方”。后面的故事大家应该都知道,不知道的去搜也就知道了。
总之,又一次,医疗大数据的应用变现之门被无情地关上了,而且还被贴了封条。
到了这一步,大多数人只能无奈作罢。简单可行的路都被堵死了,那些唾手可得的果实也不敢去摘,生怕触碰了高压线。剩下的,都是些高难度的操作,例如摩熵咨询平台的医疗数据定制化服务,需针对合作的定点医院特定需求场景去深入分析,这往往需要更广泛的数据覆盖范围、更精细的颗粒度划分,在保证真实、合法、准确的(脱敏)数据资源(HIS、LIS、EMS、PACS)下,去开展药物的研发与上市策略、市场趋势洞察与价值评估,以及临床决策支持等场景。
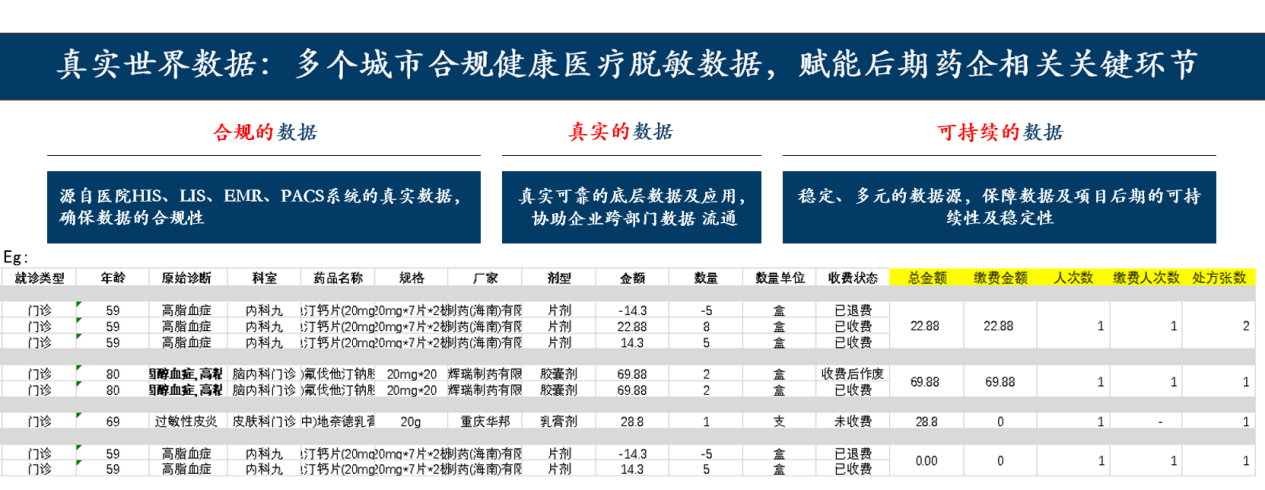
图源:摩熵医药-真实世界数据
这就是医疗大数据变现的现状。
前几年,一些新的变化正在悄然发生。国家正在紧锣密鼓地收集和规范医疗数据的使用规则,从头开始构建新的医疗数据应用生态。希望在规范医学数据使用规则的前提下,重新拉起这个目前萎靡不振但体量达千亿的市场。
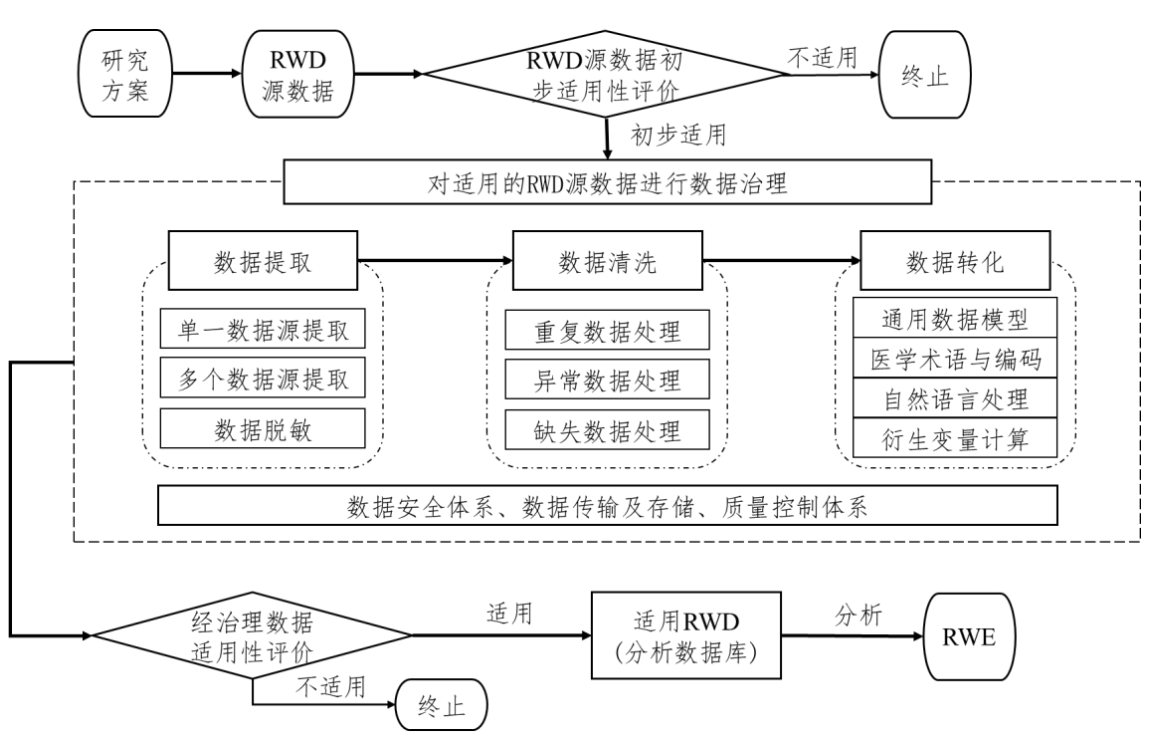
图:真实世界数据的适用性评价和数据治理过程示意图
笔者有幸参与核心的部分,谈不上多么造诣精通,但也算应对自如,汇总小土堆(ETL)、从土中筛去杂质(数据治理)、进一步精炼(数据挖掘)以及最终的价值产出(数据变现)。合法地利用海量医疗数据,为药企、保险公司、医生等提供高价值的数据视角。顺便说一句,笔者能接触到原始层面收集的多个省市医院的全数据,如果有人想从这些数据中挖掘结论,可以私我详聊。
让我们期待,在不远的未来,能有更多数据被汇集和提炼,能有更多有能力的人在保障医疗数据隐私的前提下,披荆斩棘开辟出一条轨道,把源源不断的钻石(数据价值)输送给行业的每一位参与者。
随机推荐
最新推荐